ROCm Across Different Architectures: A Step-by-Step Guide
As an intrepid hacker of things I don't understand, I'm excited to share a straightforward approach to running ROCm workloads across multiple quasi-supported GPUs with different architectures. In this article, I'll walk you through the necessary steps and provide examples to get you started.
The Challenge
Running ROCm applications across multiple GPUs from different
architectures can be challenging due to ROCm's lack of support
for most consumer GPUs. The ROCm Thunk Interface addresses this
somewhat with the HSA_OVERRIDE_GFX_VERSION
environment variable, which lets you force the use of a specific
target that might be compatible with your hardware, letting even
unsupported cards work if they're similar enough to a supported
one. However, this overrides the target for all GPUs in
the system, meaning they all have to be compatible with the one
target version, or you're likely to run into issues caused by
incompatible kernels.
I hacked together a patch that aims to fix this by allowing you to override the target version for each individual GPU in the system, letting you run any combination of "unsupported" cards in the same address space at the same time.
The Solution
I tested this solution using
rocm-hip-sdk 6.0.2-1 from Arch Linux. The patched
version is from 6.1.something, so it's already a bit of a
frankenlink, but your mileage may greatly vary depending on what
ROCm version you have.
Step 1: Build & Install
To get started, clone my patched AMD ROCm Thunk Interface from GitHub:
git clone https://github.com/AdamNiederer/ROCT-Thunk-Interface.git
cd ROCT-Thunk-Interface
git checkout per-node-overridesNext, build and install the thunk interface using the following commands:
mkdir build && cd build
cmake -DBUILD_SHARED_LIBS=on ..
make
# System libhsakmt will be backed up to libhsakmt.so.${VERSION}~
sudo install -sbm755 libhsakmt.so.1.* /opt/rocm/lib/Ensure that your libhsakmt.so and
libhsakmt.so.1 symlinks don't point to the
backed-up system version after performing these steps.
Step 2: Configure Your Workload
Now that the patched ROCm Thunk Interface is installed,
configure your workload to use it with environment variables.
When launching your application, set
HSA_OVERRIDE_GFX_VERSION_# to specify the target
version you wish to override for a particular node, where
# is the node's number. The number of each node can
be obtained via rocminfo, with the CPU usually
being node 0.
For example:
HSA_OVERRIDE_GFX_VERSION_1="11.0.0" ./your_programIn this example, we're overriding the target version for Node
1 to 11.0.0, used by most RDNA3 cards. You can
adjust the value and trailing number according to your specific
needs and the devices in your system, and specify as many of
these overrides as you'd wish
Of course, this feature is only really useful when you have multiple GPUs that need unique overrides:
HSA_OVERRIDE_GFX_VERSION_1="11.0.0" HSA_OVERRIDE_GFX_VERSION_2="10.3.0" ./your_programThis example is suitable for running an RDNA3 card alongside an RDNA2 card. The patch should let you specify up to one million nodes' overrides before the fixed-size buffer I used gets angry. If you're somehow in possession of more GPUs in the same system please let me know so I can increase the size in your honor.
In addition, you should be able to do this:
HSA_OVERRIDE_GFX_VERSION="10.3.0" HSA_OVERRIDE_GFX_VERSION_3="11.0.0" ./your_programThis example overrides the target version for all nodes to be
10.3.0 except Node 3, which is overridden to
11.0.0. The numbered variables take precedence over
the unnumbered variable.
Here's an example of LLaMA3-70B running across my RX 7900XT, RX 6600, and i5-12600k with hacked-on AVX-512, using a patched version of ollama with better multi-gpu support.
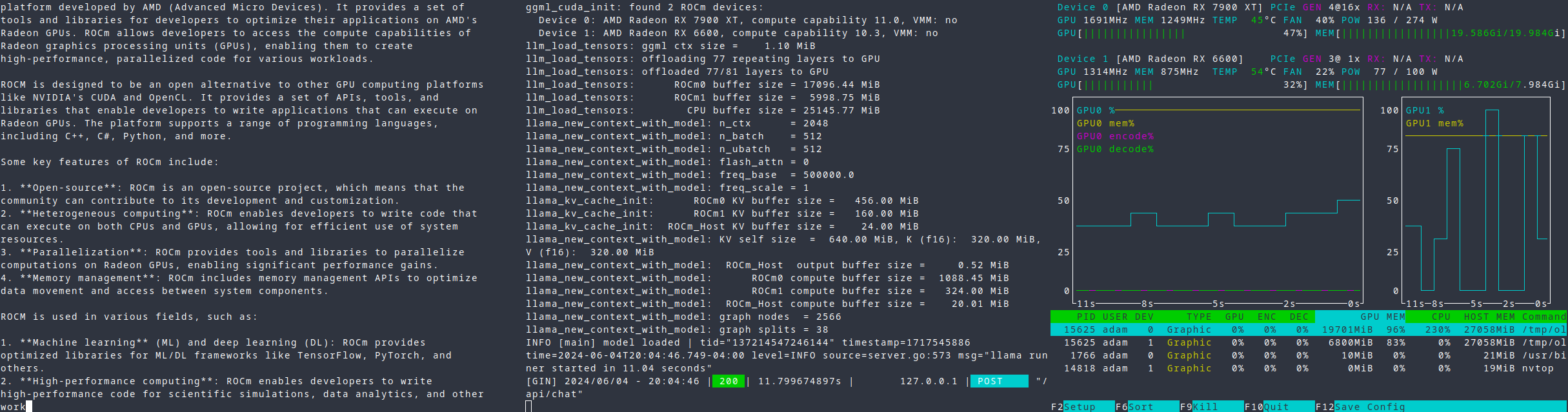
With this setup, I'm getting the following results:
- 7900 XT + 6600 + CPU: 7.4 tok/s; 77 of 81 layers offloaded
- 7900 XT + CPU: 4.3 tok/s; 57 of 81 layers offloaded
- CPU: 2.2 tok/s; 0 of 81 layers offloaded
You may get even better results on more evenly-matched cards, or if you aren't using an old PCIe 3.0 x1 riser cable for your second GPU.
Conclusion
By following these steps and examples, you should be able to run your ROCm workloads across multiple GPUs with different architectures, and better leverage hardware that you may otherwise have laying around. There are probably lots of bugs, and I dunno which bugs are my bugs. Don't use this patch in production. I hope this guide has been helpful in helping you better utilize your big pile of random GPUs. Happy coding!